(unfortunately I f’d up the date, should be 02-11-2024, not 12-07-2024, can’t change it though, otherwise the link will be changed)
With the rise of L2s like MegaETH that promise over 100k tps, I often ask myself how I would design such a system. What are the tradeoffs that we choose on L1 that an L2 could diverge from. How can we build a system that targets “good enough” on the decentralization axis while prioritizing speed and security. This exercise in creative writing tries to explore some of the ideas I had (and also why they aren’t suited for L1 but could be applicable for L2s).
Get rid of the trie
The biggest improvement (and probably the most complicated and controversial) first. We need to get rid of the trie. The state trie (and especially the state root in the header) serves three functions:
- Making sure the state transition is correct
- Provide an anchor for witnesses for light client verification
- Provide an anchor for light client proofs
- Allow for snap sync
We will tackle these functions one-by-one in reverse order.
Regarding 4: Snap sync
We use the trie for two things during snap sync. When a syncing client requests a range of accounts, we provide a proof for the first and the last account in the range.
This allows the syncing client to verify that the range of accounts (or slots) we provided matches a state root. During syncing, we might need to switch the state root that we’re requesting state for (since the chain continues on and our peers might not have that state available anymore). We call this “moving the pivot”.
After we synced all accounts, we have a lot of states in memory that references different state roots, now we need to unify them in a process we call “healing”. For that we go through our forest (collection of trees) and see which states are still correct with the latest state root and which need to be updated. We requests the updates with proofs from our peers until the whole trie is healed.
While it is a very common occurrence for nodes on L1 to provide data for other nodes to sync from, on our L2 this will not be the case. We expect only a minority of nodes to actually have the full state (the sequencer, the RPC providers and the fraud provers). Since they are expected to run powerful machines or be known entities in the ecosystem, we can either make them execute the blocks from genesis to replay the chain or send them a disk with the state on it, copied from one of our nodes.
Regarding 3: Anchor for light client proofs
Some people might not know this, but you can use eth_getProof to get a proof for your account.
This proof cryptographically proofs to you that your account is part of the state.
Most users do not use this at the moment though, they trust their RPC provider to provide them to correct state of their account.
Recently projects like Helios have started to change that, but it seems like the majority of users trust their RPC providers enough, so we don’t need to support light client proofs in our L2 by default.
We could provide either a trailing state root or accumulator in the block, which would make it possible to proof against older state. A proving service could also do this as an application on top of our L2, by periodically sending transactions that store the state root onchain.
Regarding 2: Witnesses for light client verification
Another cool thing that the state root gives you is block witnesses. With each block (both in MPT and Verkle, but in Verkle its much more practical), you can provide proofs of all the pre-state (the state before the execution) to the state root of the previous block and proofs of the post-state (after execution) to the current state root.
This way a verifier can verify the block statelessly (meaning they don’t have to have the state, just the previous state root). They (1) verify the pre-state proof to the old accepted state root (2) apply all the transactions in the block (3) verify the post-state proof (4) accept the current state root.
This is very cool and important for a maximally decentralized base-layer that needs to be verified by as many people as possible (and needs to be easily verified by L2s/other L1s for bridging etc), but its not necessary for our speed focused L2.
Regarding 3: Verifying the state transition
The third and probably most well known reason for the state trie is to verify that every node computed the same state transition. This is very important, otherwise nodes could go out of sync and no one would notice until one of the nodes rejects a transaction that the other accepts. Finding this error posthumously is very difficult and would probably require a rollback of transactions. Its always better to fail fast and loud.
I would like to preserve the ability to verify the state transition, but we can use a simple hash of the changed accounts for that. The trie is so expensive, because a single change in one of the leaves (like updating a nonce or changing a balance) requires recomputation of many nodes of the trie. The account trie for Ethereum mainnet has 10-11 layers and the biggest contract has 9-10, so in the worst case a node has to rehash 20 nodes for a single SSTORE. These nodes need to be loaded from disk, modified, rehashed and written to disk again, which produces a huge overhead.
Solution for the trie
As already foreshadowed in the previous section, we will hash all the changes that occurred in the block together and put the resulting hash into the block. This way we preserve the ability for other full nodes to verify the state transition while removing the additional overhead of hashing and writing/reading from disk. Since we will have all the changes from the state transition in memory at the end of the block, computing this hash will be very quick.
We will organize the state in a flat format, similar to the current snapshot format used by geth and other clients. There are some fancy ideas that you could do if you have control over the state format, like state expiry or Address Space Extension which might break compatibility with certain versions of solidity.
Removing receipts
Another thing I would change for our blazing fast L2 (and even for L1 for that matter) are receipts. Receipts tell you among others if a transaction succeeded, how much gas it used and any logs that were emitted (e.g. by using emit Event in solidity). They currently take up ~210GB of the 1.1TB of data that a node needs to store (and thats in the most compressed form, otherwise they would take up north of 600GB).
The receipts also serve multiple purposes. The hash of the receipts for a block (the receipts root) is stored in the header, so light clients can easily see whether a transaction succeeded or failed. The logs also make it possible to query whether certain events happen and in which block/transaction they happened. So a light client could derive queries like Give me all events involving my address and the USDC contract and a full node can provide them a proof for that.
These proofs are possible but very much underutilized in L1, so I don’t expect them to be used at all in our high performant L2. So we can easily get rid of the receipts. Logs and log filtering will still be useful and needed (for example for applications listening to events), but there can be auxiliary services that collect the logs from execution, store them in a format that can be easily queried and serve them to users.
Parallelizing computation
Another topic that many L2s are experimenting with is parallelizing computation. There are some fundamental issues with it, we don’t know at the start of the transaction which storage slots and addresses a transaction touches. Thus we don’t know which transactions can be executed in parallel and which transactions need to be executed sequentially. Some protocols solve this, by just executing everything in parallel and re-executing the conflicting transactions afterwards. This has a big issue, since you can always create a set of transactions that conflict with each other, so the transaction execution needs to be linearized in the worst case anyway. In my opinion, this way of parallelizing computation can only help the average case, never the worst case, so we can not safely increase the gas limit if we add it.
Another idea that often comes up is to make accesslists mandatory. Transactions can (already in L1) be augmented with optional accesslists. These lists contain addresses of accounts that the transaction might touch. Since they are optional, we can not make any decisions based on them. However we could make them mandatory. This would force the transaction sender to explicitly specify which accounts will be touched by their transaction and if the transaction touches other accounts, the transaction will fail (be reverted).
All this is well and good, but transaction senders might not know at the time of sending which accounts the transaction will end up interacting with. So what I propose for our high-performant L2 is the following structure:
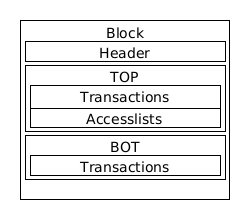
We split the block into two parts: TOP and BOT. Top can only contain transactions with mandatory access lists that have no conflicts and Bot can contain transactions with or without mandatory access lists. Transactions with access lists will only end up in BOT if they are conflicting with transactions in Top. The size of the two parts are dynamic. The transactions in Top can be executed in parallel while the transactions in Bot can only be optimistically executed in parallel. We can give a discount to transactions in the Top part of the block, since they are guaranteed to be executed in parallel. This will implicitly reward users that use the mandatory access lists, since you are only eligible to be in the Top with them.
Getting rid of the network stack of the sequencer node
We assume that the centralized sequencer receives all transactions via a central (or multiple) RPCs, we can remove the transaction propagation (and with it the whole current network stack of the sequencer). These RPCs can also do basic validation on the transactions before they forward the transactions to the sequencer, which would help to scale the sequencer even more, since it doesn’t need to perform these additional responsibilities. They could also annotate the transactions with additional fields (like the recovered sender), so the sequencer doesn’t need to do any signature recovery. The RPC nodes could also provide a receipt that the transaction was submitted to the user, which can be used to proof censorship of the sequencer.
Blocks will be send from the sequencer to another node which could then distribute them via a decentralized network (maybe even via protocols like bittorrent) to all interested parties (verifying nodes, history archive nodes and RPC nodes).
Conclusion
In conclusion our highly scalable L2 would remove a bunch of features that make L2 trustlessly verifiable in order to achieve the required throughput. We would remove the merkelization of the state, remove receipts and the receipt root, and make part of the block executable in parallel by adding a new transaction type with mandatory access lists. History, RPCs and access to event logs will be provided by trusted third parties (similar what most users use right now).
The sequencer will be insulated from all other additional services which makes vertical scaling of the sequencer easier. Following sketch tries to illustrate the architecture:
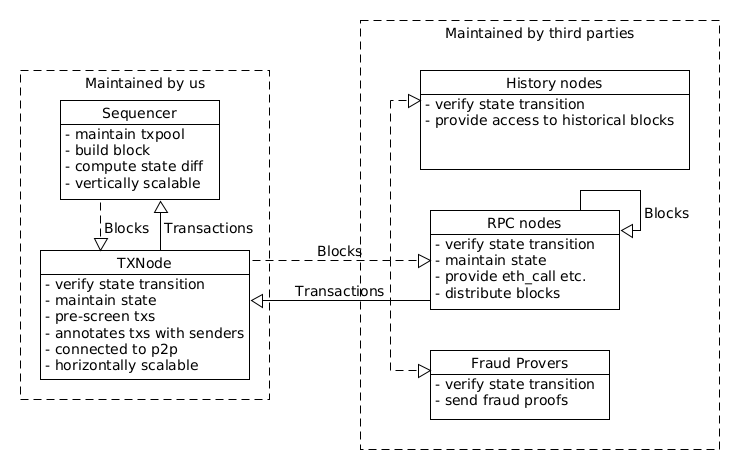
There are a few missing design pieces that I did not address yet, especially how fraud proofs would work with our high performant L2, but since most L2s don’t have them live either, they will remain an exercise to the reader :P.
In general an L2 built like this will achieve significantly higher throughput while having higher trust assumptions